
To our surprise, label errors are pervasive across 10 popular benchmark test sets used in most machine learning research, destabilizing benchmarks.
It’s well-known that ML datasets are not perfectly labeled. But there hasn’t been much research to systematically quantify how error-ridden the most commonly-used ML datasets are at scale. Prior work has focused on errors in train sets of ML datasets. But no study has looked at systematic error across the most-cited ML test sets — the sets we rely on to benchmark the progress of the field of machine learning.
Here, we algorithmically identified and human-validated that there are indeed pervasive label errors in the ten of the most-cited test sets, then studied how they affect the stability of ML benchmarks. Here we summarize our findings along with key takeaways for ML practitioners.
This post overviews the paper Pervasive Label Errors in Test Sets Destabilize ML Benchmarks authored by Curtis G. Northcutt (Cleanlab & MIT), Anish Athalye (MIT), and Jonas W. Mueller (Amazon).
Errors in Highly-Cited Benchmark Test Sets
Browse all label errors across all 10 ML datasets at labelerrors.com (demos below):
Key Takeaways of Pervasive Label Errors
How pervasive are errors in ML test sets?
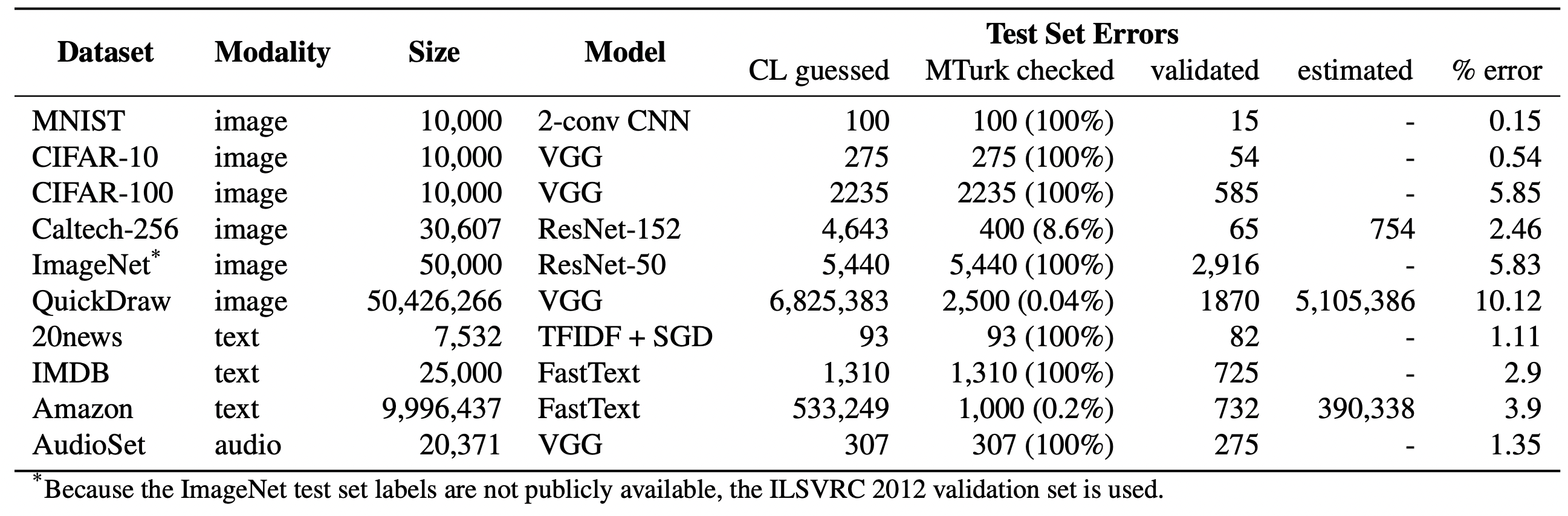
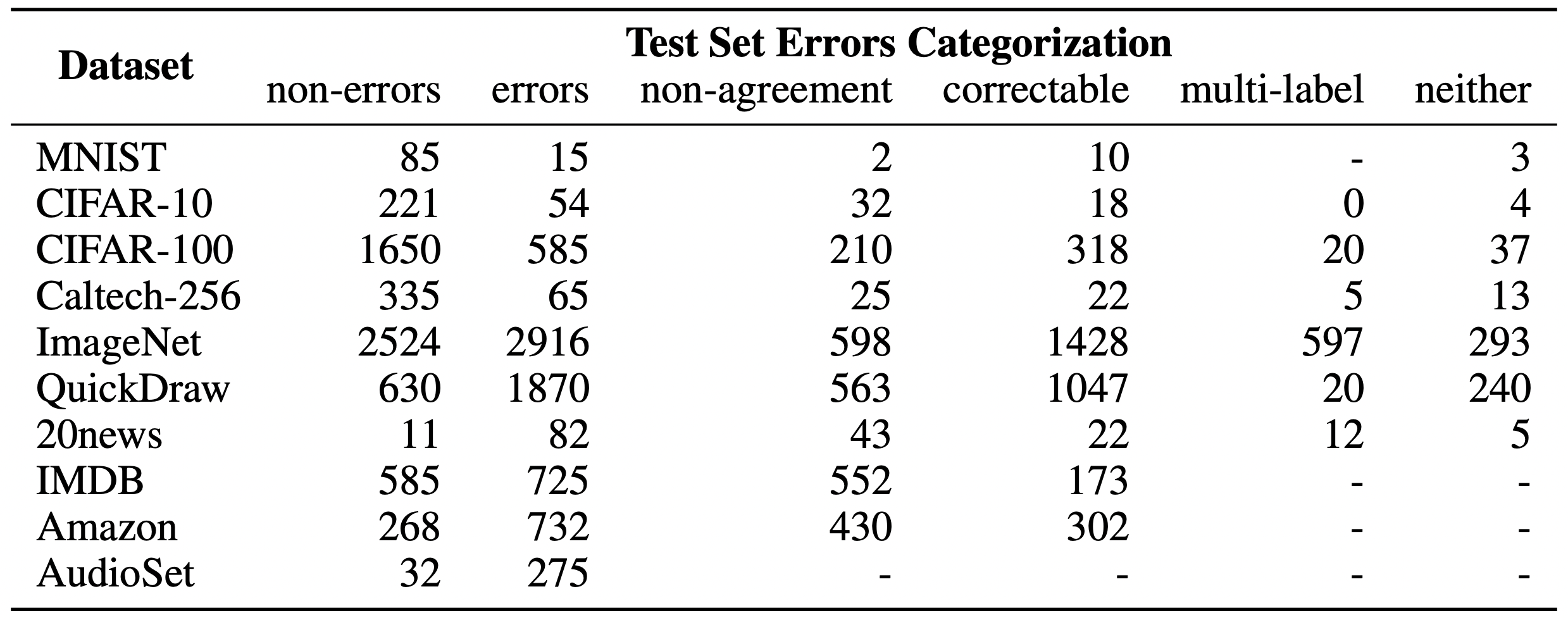
- We estimate an average of 3.4% errors across the 10 datasets, where for example 2,916 label errors comprise 6% of the CIFAR-100 test set and ~390,000 label errors comprise ~4% of the Amazon Reviews dataset. Even the MNIST dataset, assumed to be error-free and benchmarked in tens of thousands of peer-reviewed ML publications, contains 15 (human-validated) label errors in the test set.
Is a corrected version of each test set available?
- Yes, Click here for the corrected test sets. In these corrected test sets, humans on MTurk corrected a large fraction of the label errors. We hope future research on these benchmarks will use these improved test sets instead of the original erroneously labelled datasets. Note you will have to construct the corrected test set from the M-turk file (we don’t do this for you since you may want to only correct examples where all 5 Mturk reviewers agreed, or just 3 of 5 reviewers agreed, so we leave this for you to decide).
Of the 10 ML datasets you looked at, which had the most errors?
- The QuickDraw test set contains over 5 million errors comprising about 10% of the test set. View the QuickDraw label errors.
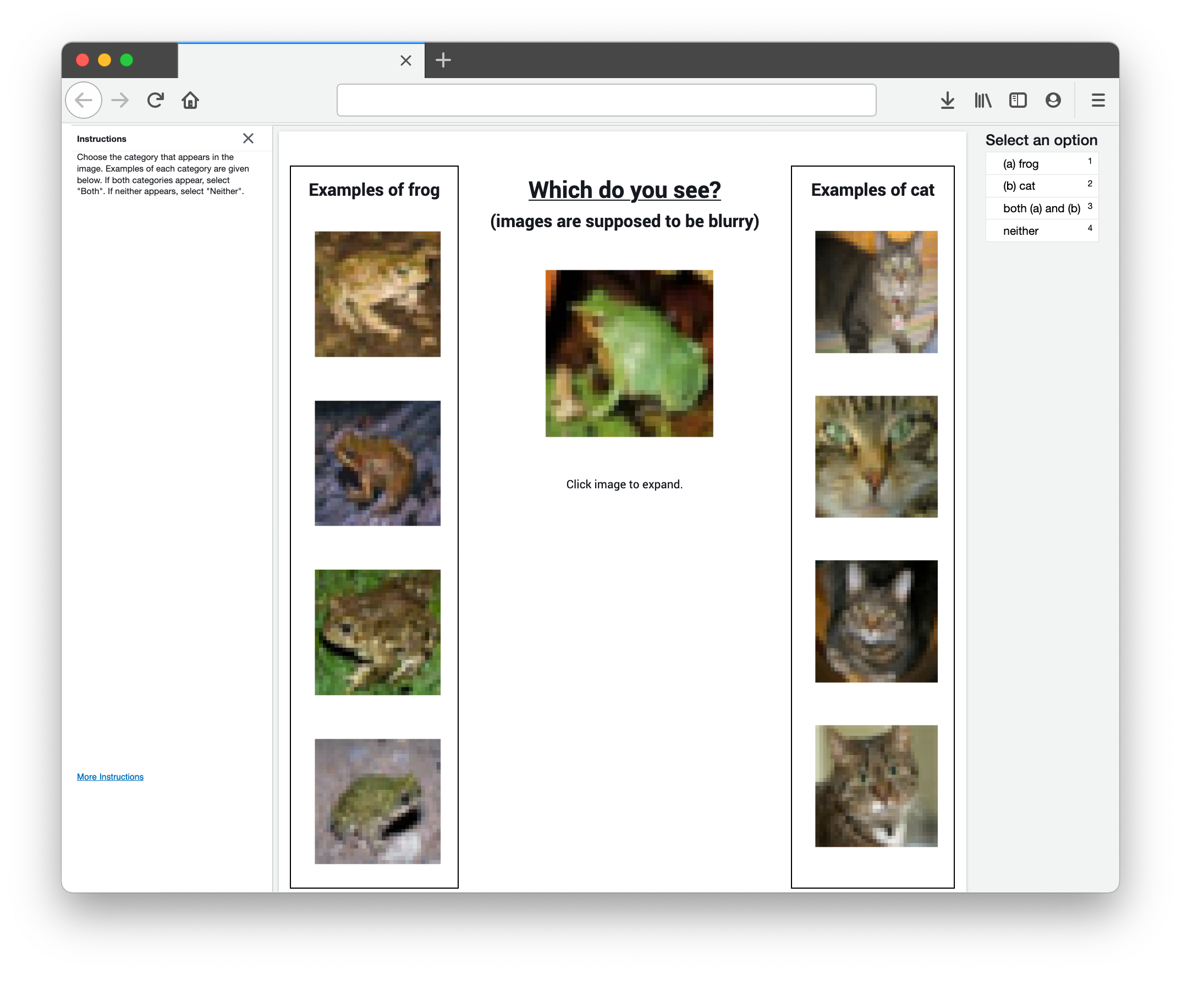
How did you find label errors in vision, text, and audio datasets?
- In all 10 datasets, label errors are identified algorithmically using confident learning and then human-validated via crowd-sourcing (54% of the algorithmically flagged candidates are indeed erroneously labeled). The confident learning framework is not coupled to a specific data modality or model, allowing us to find label errors in many kinds of datasets.
What are the implications of pervasive test set label errors?
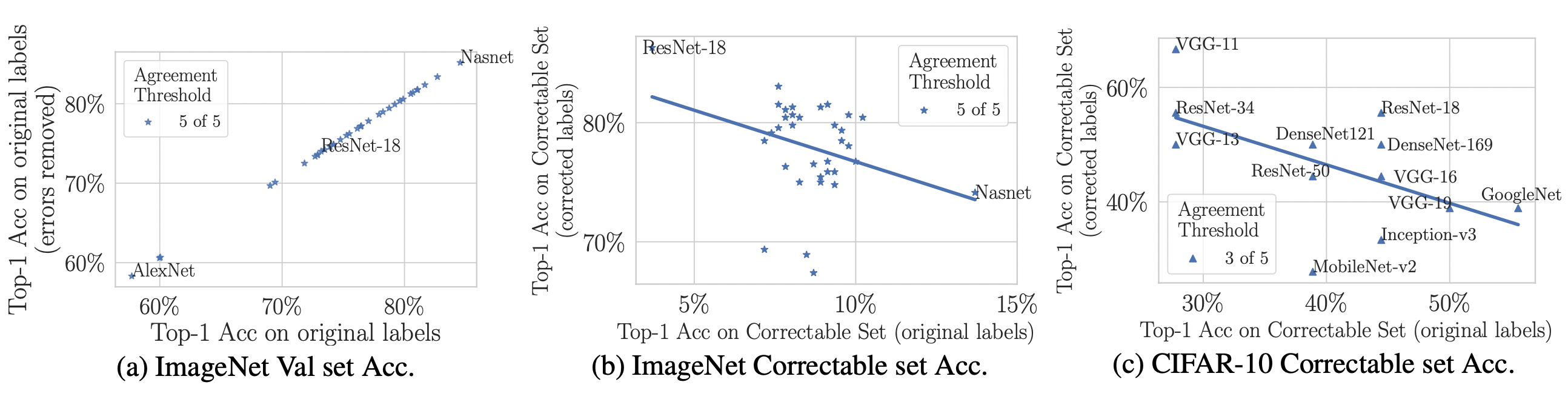
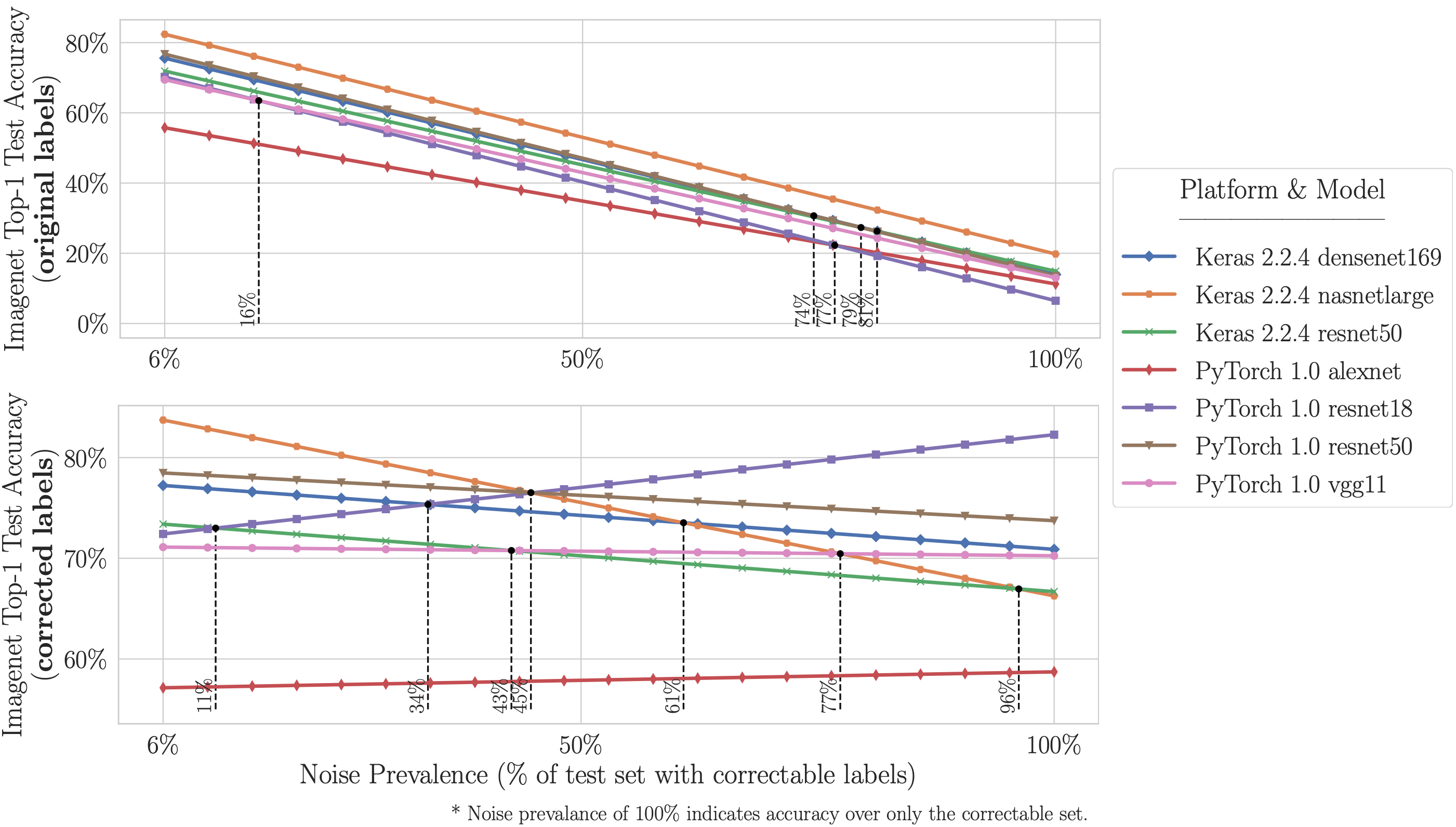
- Higher capacity/complex models (e.g. ResNet-50) perform better on the original incorrectly labeled test data (i.e. what one traditionally measures), but lower capacity models (e.g. ResNet-18) yield higher accuracy on corrected labels (i.e. what one cares about in practice, but cannot measure without the manually corrected test data we provide). This likely occurs because higher capacity models overfit to the train set label noise during training and/or overfit to the validation/test set by tuning hyper-parameters on the test set (even though the test set is supposedly unseen).
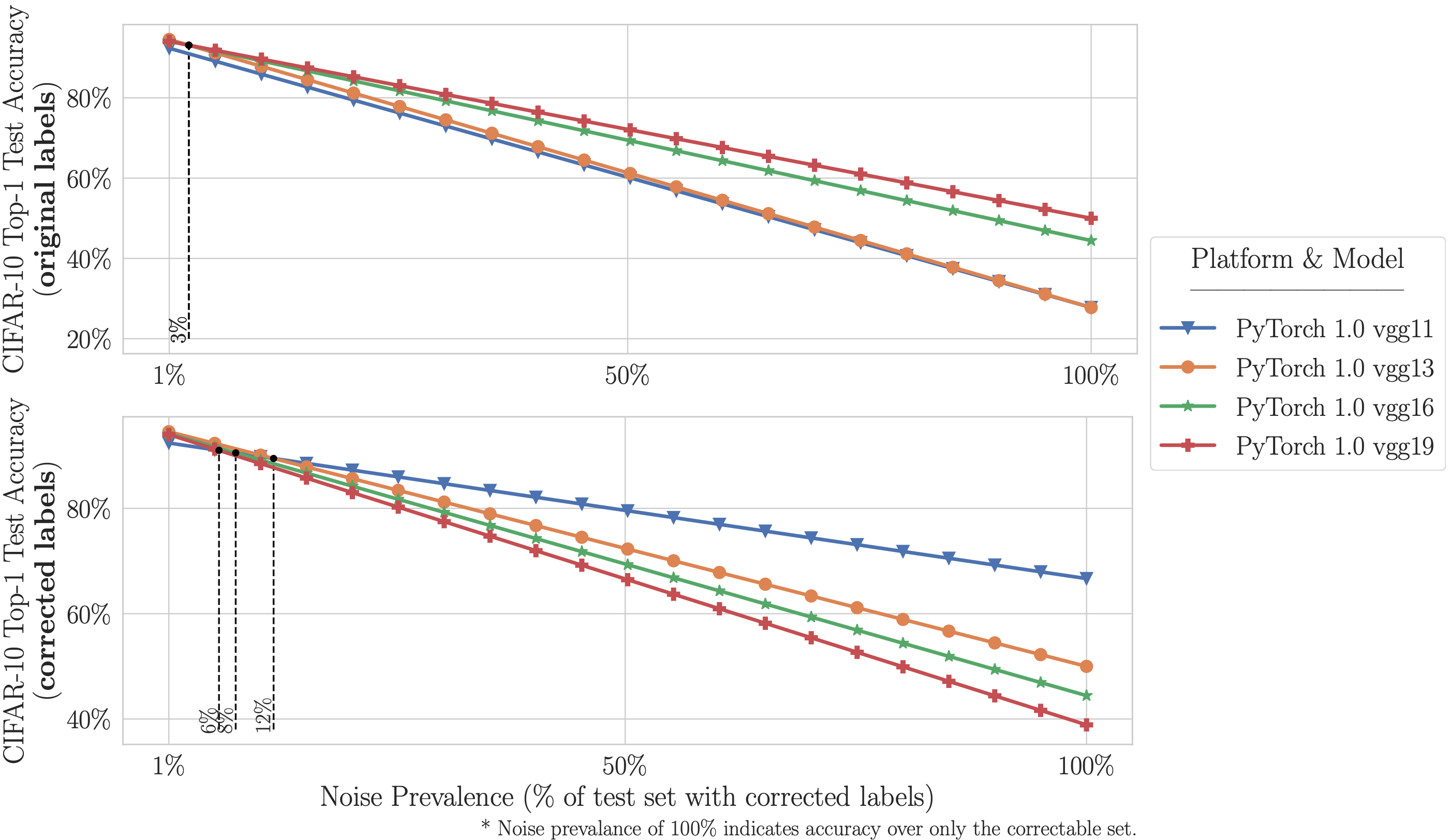
How much noise can destabilize ImageNet and CIFAR benchmarks?
- On ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of mislabeled test examples increases by 5%.
Can I interact with the label errors in each dataset?
- Yes! Errors from the ten ML test sets we analyzed are viewable at labelerrors.com. To hear audio errors, select “Dataset: AudioSet.” To view natural language (text) errors, choose a dataset from [“20news”, “IMDB”, and “Amazon”]. To view computer vision (image) errors, choose from [“MNIST”, “CIFAR-10”, “CIFAR-100”, “Caltech-256”, “ImageNet”, and “QuickDraw”].
Are the label errors 100% accurate?
- Results are not perfect. In some cases, Mechanical Turk workers agree on the wrong label. We still likely only capture a lower bound on the error given that we only validated a small fraction of the datasets for errors. Although our corrected labels are not 100% accurate, on inspection, they appear vastly superior to the original labels.
What should ML practitioners do differently?
Traditionally, ML practitioners choose which model to deploy based on test accuracy — our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets. We provide two recommendations for ML practitioners:
- Correct your test set labels (e.g. using our approach)
- to measure the real-world accuracy you care about in practice.
- to find out whether your dataset suffers from destabilized benchmarks.
- Consider using simpler/smaller models for datasets with noisy labels
- especially for applications trained/evaluated with labeled data that may be noisier than gold-standard ML benchmark datasets.
Finding Label errors
Human-validation of label errors
Effects of Test Label Errors on Benchmarks
Instability of ML Benchmarks
Learn more
A detailed discussion of this work is available in [our arXiv paper].
These results build upon a wealth of work done at MIT in creating confident learning, a sub-field of machine learning that looks at datasets to find and quantify label noise. For this project, confident learning is used to algorithmically identify all of the label errors prior to human verification.
We made it easy for other researchers to replicate their results and find label errors in their own datasets using cleanlab, an open-source python package for machine learning with noisy labels.
Related Work
- Introduction to Confident Learning: [view this post]
- Introduction to cleanlab Python package for ML with noisy labels: [view this post]
Acknowledgments
This work was supported in part by funding from the The MIT-IBM Watson AI Lab, MIT Quanta Lab, and the MIT Quest for Intelligence. We thank Jessy Lin for her help with early versions of this work (accepted as a workshop paper at NeurIPS 2020 Workshop on Dataset Curation and Security).
Comments