We often deal with label errors in datasets, but no common framework exists to support machine learning research and benchmarking with label noise. Announcing cleanlab: a Python package for finding label errors in datasets and learning with noisy labels. cleanlab cleans labels.
cleanlab on GitHub: [LINK].
cleanlab is a framework for confident learning (characterizing label noise, finding label errors, fixing datasets, and learning with noisy labels), like how PyTorch and TensorFlow are frameworks for deep learning.
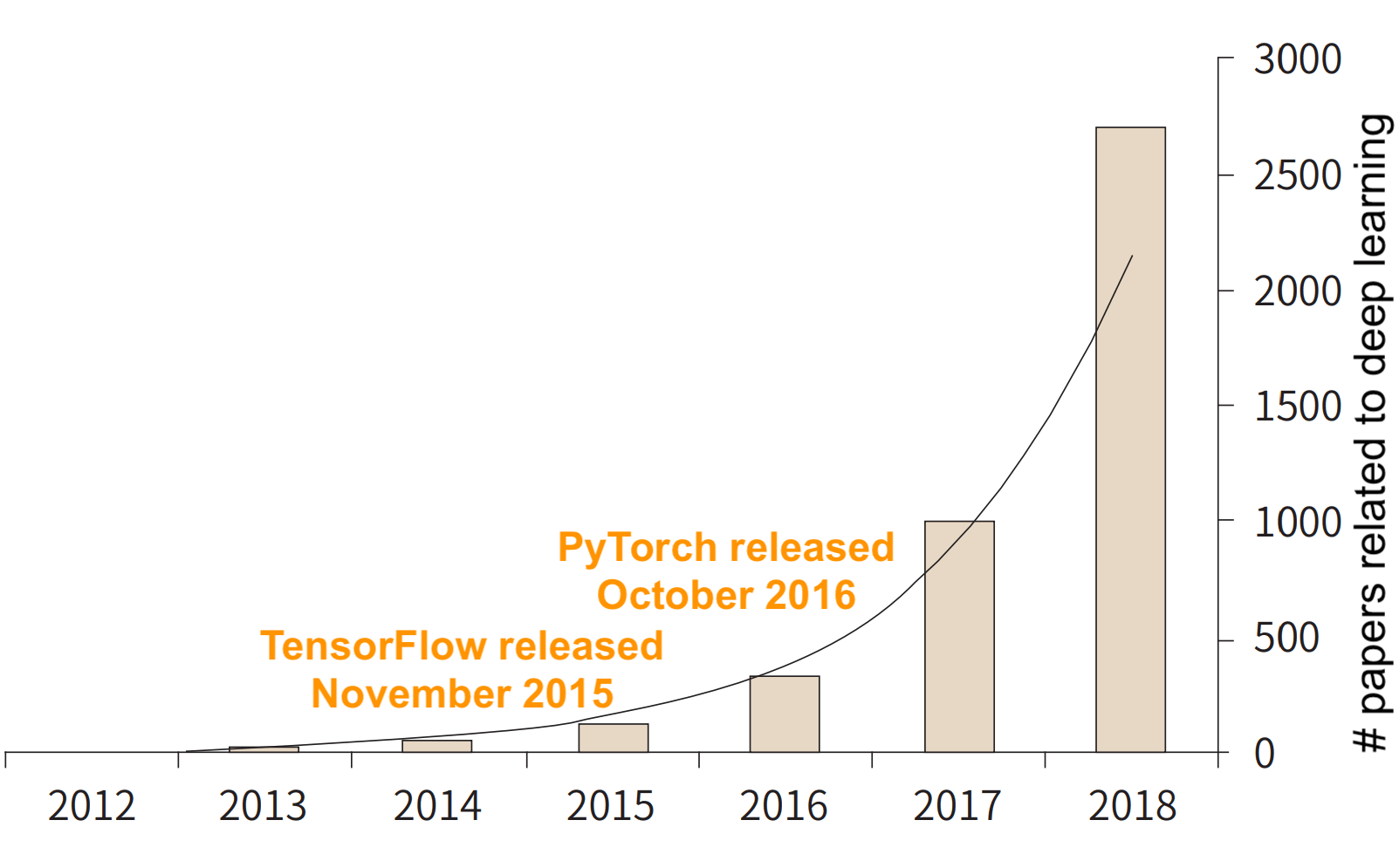
Paper counts are taken from PubMed. Source: DOI: 10.3348/jksr.2019.80.2.202.
The figure above shows how the introduction of TensorFlow and PyTorch accelerated deep learning research. cleanlab was created to do the same for the rapidly growing branches of machine learning and deep learning research that deal with noisy labels. Examples include learning with noisy labels, weak supervision, uncertainty and robustness in deep visual learning, and learning with limited data.
This post focuses on the cleanlab package. You can learn more about confident learning (the theory and algorithms behind cleanlab) in this post which overviews this paper. A numpy for-loop implementation of confident learning is available in this tutorial in cleanlab.
cleanlab, in a nutshell 🌰
cleanlab finds and cleans label errors in any dataset using state-of-the-art algorithms to find label errors, characterize noise, and learn in spite of it. cleanlab is fast: its built on optimized algorithms and parallelized across CPU threads automatically. cleanlab is powered by provable guarantees of exact noise estimation and label error finding in realistic cases when model output probabilities are erroneous. cleanlab supports multi-label, multiclass, sparse matrices, etc. By default, cleanlab requires no hyper-parameters.
$ # install cleanlab in any bash terminal using pip
$ pip install cleanlab
cleanlab works with any ML or deep learning model because there are only two inputs:
- a matrix of out-of-sample predicted probabilities for each example, for every class
- an array of noisy labels for each example
Throughout the code base, the function parameter s refers to the numpy.array of noisy labels (versus typical ML packages that use y, reserved for true, uncorrupted labels). psx refers to the matrix of predicted probabilities using the noisy labels.
Note: The code presented in this blog is from an older version of cleanlab. Get started using the latest version of cleanlab here. Since this blog was published, cleanlab has grown beyond label errors into a general data-centric AI library that can automatically detect various data and label issues in most ML datasets.
How to find label errors with PyTorch, TensorFlow, scikit-learn, MXNet, FastText, or other framework in 1 line of code.
# Compute psx (n x m matrix of predicted probabilities)
# in your favorite framework on your own first, with any classifier.
# Be sure to compute psx in an out-of-sample way (e.g. cross-validation)
# Label errors are ordered by likelihood of being an error.
# First index in the output list is the most likely error.
from cleanlab.pruning import get_noise_indices
ordered_label_errors = get_noise_indices(
s=numpy_array_of_noisy_labels,
psx=numpy_array_of_predicted_probabilities,
sorted_index_method='normalized_margin', # Orders label errors
)
Learning with noisy labels in 3 lines of code!
from cleanlab.classification import LearningWithNoisyLabels
from sklearn.linear_model import LogisticRegression
# Wrap around any classifier (scikit-learn, PyTorch, TensorFlow, FastText, etc.)
lnl = LearningWithNoisyLabels(clf=LogisticRegression())
lnl.fit(X=X_train_data, s=train_noisy_labels)
# Estimate the predictions you would have gotten by training with *no* label errors.
predicted_test_labels = lnl.predict(X_test)
The cleanlab.classification.LearningWithNoisyLabels module works out-of-box with all scikit-learn classifiers. If you want to use the above code with PyTorch, TensorFlow, MXNet, etc., you need to wrap your model in a Python class that inherits the sklearn.base.BaseEstimator like this:
from sklearn.base import BaseEstimator
class YourFavoriteModel(BaseEstimator): # Inherits scikit-learn base classifier
'''Let's your model be used by LearningWithNoisyLabels'''
def __init__(self, ):
pass
def fit(self, X, y, sample_weight = None):
pass
def predict(self, X):
pass
def predict_proba(self, X):
pass
def score(self, X, y, sample_weight = None):
pass
# Now you can use `cleanlab.classification.LearningWithNoisyLabels` like this:
from cleanlab.classification import LearningWithNoisyLabels
lnl = LearningWithNoisyLabels(clf=YourFavoriteModel())
lnl.fit(train_data, train_labels_with_errors)
Some libraries like the skorch package do this automatically for you.
Working example of a compliant PyTorch MNIST CNN class: [LINK].
Check out these examples and tests.
Citing cleanlab
If you use cleanlab in your work, please cite this paper:
@misc{northcutt2019confidentlearning,
title={Confident Learning: Estimating Uncertainty in Dataset Labels},
author={Curtis G. Northcutt and Lu Jiang and Isaac L. Chuang},
year={2019},
eprint={1911.00068},
archivePrefix={arXiv},
primaryClass={stat.ML}
}
Examples
Find Label Errors in the MNIST dataset
These cleanlab examples: [LINK], demonstrate how to find label errors in MNIST.

The figure above depicts errors in the MNIST train dataset identified algorithmically using the rankpruning algorithm. Depicts the 24 least confident labels, ordered left-right, top-down by increasing self-confidence (probability of belonging to the given label), denoted conf in teal. The label with the largest predicted probability is in green. Overt errors are in red.
cleanlab Performance on 4 Datasets across 9 Models
We use cleanlab to learn with noisy labels for various dataset distributions and classifiers.

Each sub-figure in the figure above depicts the decision boundary learned using cleanlab.classification.LearningWithNoisyLabels in the presence of extreme (~35%) label errors. Label errors are circled in green. Label noise is class-conditional (not simply uniformly random). Columns are organized by the classifier used, except the left-most column which depicts the ground-truth dataset distribution. Rows are organized by dataset used.
At the top of each sub-figure accuracy scores on a test set are depicted:
- LEFT (in black): Classifier test accuracy trained with perfect labels (no label errors).
- MIDDLE (in blue): Classifier test accuracy trained with noisy
labels using
cleanlab. - RIGHT (in white): Baseline classifier test accuracy trained with noisy labels.
The code to reproduce this figure is available here.
Getting Started with cleanlab
The cleanlab package includes a number of examples to get you started. If you’re not sure where to start, try checking out how to find ImageNet Label Errors.
Examples and tutorial available in cleanlab include:
/examples/imagenet,/examples/mnist,/examples/cifar10- code to find label errors in these datasets and reproduce the results in the confident learning paper. You need to
git cloneconfidentlearning-reproduce. /examples/imagenet/imagenet_train_crossval.py- a powerful script to train cross-validated predictions on ImageNet, combine cv folds, train with on masked input (train without label errors), etc.
/examples/cifar10/cifar10_train_crossval.py- same as above, but for CIFAR.
- code to find label errors in these datasets and reproduce the results in the confident learning paper. You need to
/examples/classifier_comparison.ipynb- tutorial showing
cleanlabperformance across 10 classifiers and 4 dataset distributions.
- tutorial showing
/examples/iris_simple_example.ipynb- tutorial showing how to use
cleanlabon the simple IRIS dataset.
- tutorial showing how to use
/examples/model_selection_demo.ipynb- tutorial showing model selection on the cleanlab’s parameter settings.
/examples/simplifying_confident_learning_tutorial.ipynb- tutorial implementing cleanlab as raw numpy code.
/examples/visualizing_confident_learning.ipynb- tutorial to demonstrate the noise matrix estimation performed by cleanlab.
Core Package Components
/cleanlab/classification.py- The LearningWithNoisyLabels() class for learning with noisy labels.
/cleanlab/latent\_algebra.py- Mathematical equalities and computations when noise information is known.
/cleanlab/latent\_estimation.py- Estimates and fully characterizes all statistics dealing with label noise.
/cleanlab/noise\_generation.py- Generate mathematically valid synthetic noise matrices.
/cleanlab/polyplex.py- Characterizes joint distribution of label noise exactly from noisy channel.
/cleanlab/pruning.py- Finds the indices of the examples with label errors in a dataset.
For extensive documentation, see method docstrings.
Other Things You Can Do with cleanlab
These examples may require some domain knowledge about the main statistics used in uncertainty estimation for dataset labels. See ([LINK to paper]).
Estimate Latent Statistics about Label Noise
Examples of latent statistics in uncertainty estimation for dataset labels are the:
- confident joint
- unnormalized estimate of the joint distribution of noisy labels and true labels
- noisy channel
- a class-conditional probability dist. mapping true classes to noisy classes
- inverse noise matrix
- a class-conditional probability dist. mapping noisy classes back to true classes
- latent prior
- the unknown prior of true labels (the prior of noisy labels is known)
cleanlab can compute these for you. The next few examples show how.
Compute cross-validated probabilities, the confident joint, and the statistics used in uncertainty estimation for dataset labels.
from cleanlab.latent_estimation import (
estimate_latent, estimate_confident_joint_and_cv_pred_proba
)
# Compute the confident joint and psx (n x m predicted probabilities matrix),
# for n examples, m classes.
confident_joint, psx = estimate_confident_joint_and_cv_pred_proba(
X=X_train,
s=train_labels_with_errors,
clf=logreg(), # default, you can use any classifier
)
# Estimate the latent statistics (distributions)
# - Latent Prior: est_py is the array p(y)
# - Noisy Channel / Noise Transition Matrix: est_nm is the matrix P(s|y)
# - Inverse Noise Matrix: est_inv is the matrix P(y|s)
est_py, est_nm, est_inv = estimate_latent(
confident_joint, s=train_labels_with_errors)
You can do everything above in a single function.
from cleanlab.latent_estimation import (
estimate_py_noise_matrices_and_cv_pred_proba
)
est_py, est_nm, est_inv, confident_joint, psx = (
estimate_py_noise_matrices_and_cv_pred_proba(
X=X_train,
s=train_labels_with_errors,
)
)
If you already have predicted probabilities (e.g. from PyTorch), then…
# Already have psx? (n x m matrix of predicted probabilities)
# For example, the outputs of a pre-trained ResNet on ImageNet
from cleanlab.latent_estimation import (
estimate_py_and_noise_matrices_from_probabilities
)
est_py, est_nm, est_inv, confident_joint = (
estimate_py_and_noise_matrices_from_probabilities(
s=train_labels_with_errors,
psx=psx,
)
)
Completely characterize label noise in a dataset:
The joint probability distribution of noisy and true labels, P(s,y), completely characterizes label noise with a class-conditional m x m matrix.
from cleanlab.latent_estimation import estimate_joint
joint = compute_confident_joint(
s=noisy_labels,
psx=probabilities,
confident_joint=None, # Provide if you have it already
)
Methods to Standardize Research with Noisy Labels
cleanlab supports a number of functions to generate noise for benchmarking and standardization in research. This next example shows how to generate valid, class-conditional, unformly random noisy channel matrices:
# Generate a noise matrix (guarantees learnability)
from cleanlab.noise_generation import generate_noise_matrix_from_trace
noise_matrix = generate_noise_matrix_from_trace(
K=number_of_classes,
trace=float_value_greater_than_1_and_leq_K,
py=prior_of_y_actual_labels_which_is_just_an_array_of_length_K,
frac_zero_noise_rates=float_from_0_to_1_controlling_sparsity,
)
# Check if a noise matrix is learnable
from cleanlab.noise_generation import noise_matrix_is_valid
is_valid = noise_matrix_is_valid(
noise_matrix=noise_matrix,
py=prior_of_y_which_is_just_an_array_of_length_K,
)
For a given noise matrix, this example shows how to generate noisy labels. Methods can be seeded for reproducibility.
# Generate noisy labels using the noise_marix.
# Guarantees exact amount of noise in labels.
from cleanlab.noise_generation import generate_noisy_labels
s_noisy_labels = generate_noisy_labels(
y=y_hidden_actual_labels,
noise_matrix=noise_matrix,
)
Conclusion
cleanlab provides a common framework for machine learning and deep learning researchers and engineers working with datasets that have label errors. If you’d like to contribute, send a pull request on GitHub. Thanks!
Comments